
GraphQL, promesse magique ou nuage de fumée ? (2/2)
Suite de l'article à propos de GraphQL, initialement paru dans le n°242 de Programmez!
GraphQL : une base de données graphe
GraphQL repose sur la notion de graphe. En effet on peut voir l’enchaînement des resolvers comme le parcours d’un graphe, d’où la question : que se passe-t-il avec un backend supporté par une base graphe ? Je me suis alors tourné vers Neo4j que nous connaissons déjà chez SQLI. Quelle chance, il y a un plugin GraphQL ! Et, du fait que nous sommes en présence d’une application et d’un langage « graphe », il serait assez logique qu’à 1 requête GraphQL le plugin fasse correspondre 1 requête Cipher (langage de requêtage de Neo4j). Nous éliminerions alors le gros inconvénient rencontré avec la base relationnelle. Précision : du fait du plugin, nous n’avons pas besoin de backend Java pour aiguiller les requêtes.
Qu'est-ce qu'une base graphe ?
Citons Wikipédia :
Par définition, une base de données orientée graphe correspond à un système de stockage capable de fournir une adjacence entre éléments voisins : chaque voisin d'une entité est accessible grâce à un pointeur physique. C'est une base de données orientée objet adaptée à l'exploitation des structures de données de type graphe ou dérivée, comme des arbres.
Une autre manière « simpliste » de le dire est : une base graphe privilégie les relations.
Tutoriel : mise en place du plugin GraphQL
De la même manière que pour l’implémentation Java, il faut fournir le schéma représentant les relations entre les entités. Pour notre exemple :
CALL graphql.idl(' type Film { id: Long! titre: String titreFr: String duree: Int annee: Int synopsis: String type: String voteMoyenne: Float voteNombre: Int imdbId: String votes: [Vote] @relation(name:"NOTE",direction:IN) studio: Studio @relation(name:"PRODUIT",direction:IN) personnages: [Personnage] @relation(name:"FIGURE_DANS",direction:IN) realisateurs: [Personne] @relation(name:"REALISE", direction:IN) scenaristes: [Personne] @relation(name:"SCENARISE", direction:IN) }
type Personnage { id: Long! nom: String! hero: Boolean film: Film! @relation(name:"FIGURE_DANS") acteurs: [Personne!]! @relation(name:"INTERPRETE", direction:IN) }
type Personne { id: Long! nom: String! anneeNaissance: Int anneeDeces: Int imdbId: String personnages: [Personnage] @relation(name:"INTERPRETE") filmRealises: [Film] @relation(name:"REALISE") filmScenarises: [Film] @relation(name:"SCENARISE") }
type Studio { id: Long! nom: String! films: [Film] @relation(name:"PRODUIT") }
type Vote { id: Long! note: Int! critique: String film: Film! @relation(name:"NOTE") } ')
Profitons de l’existence d’une commande pour vérifier :
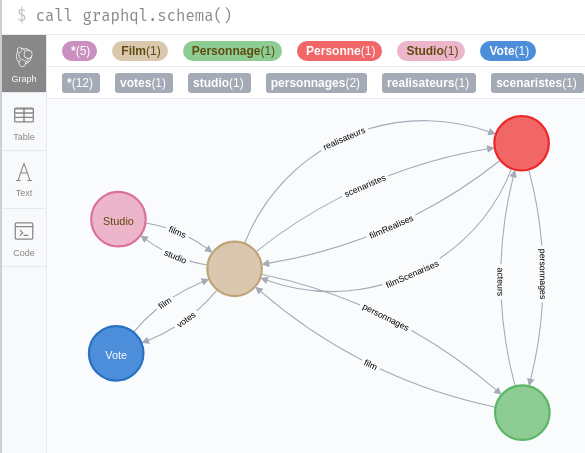
Nous constatons que les relations entre nœuds sont correctement définies.
Illustration
Une fois la base des films chargée, partons à la recherche des films joués par les acteurs du film d’identifiant 1518508, « Angel Has Fallen » via la requête cipher :
MATCH (f:Film{id:1518508})<-[:FIGURE_DANS]-(pa:Personnage)<-[:INTERPRETE]-(pe:Personne)-[:INTERPRETE]->(pa2:Personnage)-[:FIGURE_DANS]->(f2:Film) RETURN f,pa,pe,pa2,f2
Le résultat est présenté sous forme de graphe :
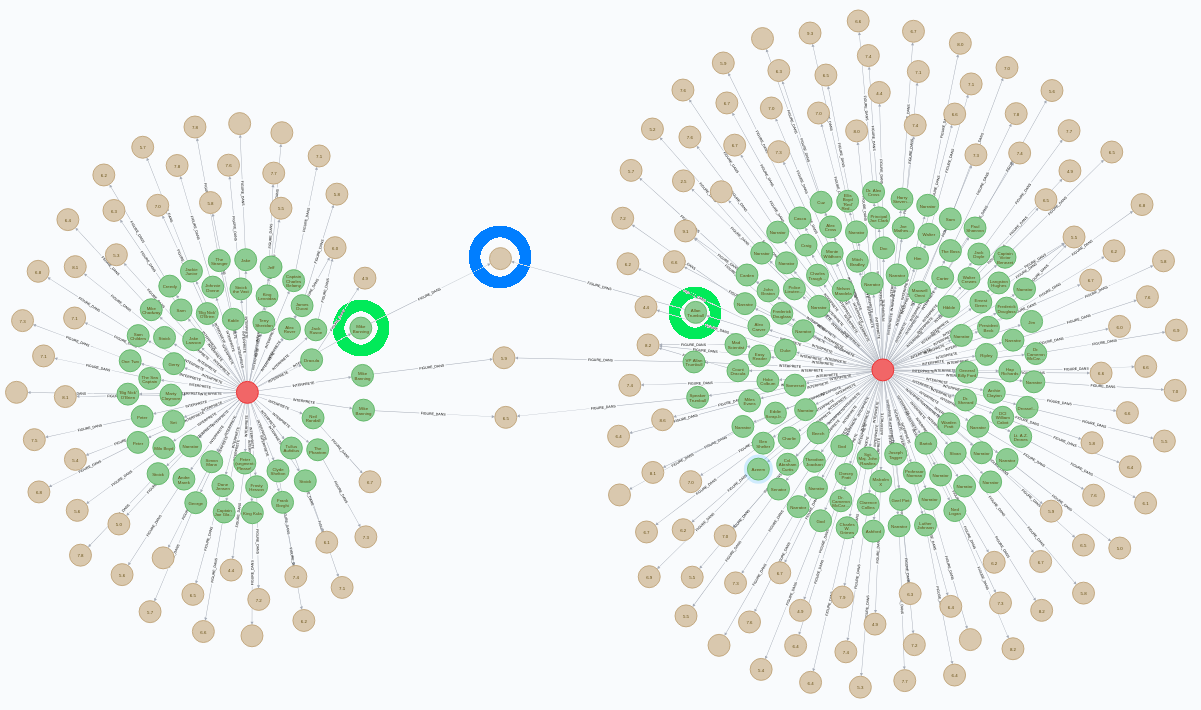
Analysons le résultat :
- Le point de recherche est cerclé de bleu ;
- De là partent les deux personnages, cerclés de vert ;
- À ces personnages sont liés les acteurs, les points rouges ;
- Pour chaque acteur nous voyons les personnages qu’ils ont joués dans leur carrière, les points verts ;
- Et, finalement, pour chaque personnage est présenté le film dans lequel il figure, les points beiges.
Notons que les trois films reliés aux deux « galaxies » entourent chacun de nos acteurs. Cela signifie qu’ils ont participé tous les deux à ces trois films. Effectivement, le film que nous avons recherché fait partie d’une trilogie : « Olympus/London/Angel Has Fallen », respectivement sortis en 2013, 2016 et 2019. Cet exemple simple laisse entrevoir la puissance de cette architecture.
Performances de GraphQL
Plus besoin de s’encombrer des étapes d’explications, lançons le test de performance sur la « grosse » requête. La moyenne du temps d’exécution est de 1,6 seconde. Tout ça sans avoir personnalisé ou optimisé quoi que ce soit. Un petit tour dans les journaux d’exécution nous révèle qu’il n’y a eu qu’une seule requête exécutée par le moteur :
MATCH (`film`:`Film`) WHERE `film`.`titreFr` = "Alice au pays des merveilles" RETURN graphql.labels(`film`) AS `_labels`, `film`.`id` AS `id`, `film`.`titre` AS `titre`, `film`.`annee` AS `annee`, [ (`film`)<-[:`FIGURE_DANS`]-(`film_personnages`:`Personnage`) | `film_personnages` {`_labels` : graphql.labels(`film_personnages`), .`nom`, `acteurs` : [ (`film_personnages`)<-[:`INTERPRETE`]-(`film_personnages_acteurs`:`Personne`) | `film_personnages_acteurs` {`_labels` : graphql.labels(`film_personnages_acteurs`), .`nom`, `personnages` : [ (`film_personnages_acteurs`)-[:`INTERPRETE`]->(`film_personnages_acteurs_personnages`:`Personnage`) | `film_personnages_acteurs_personnages` {`_labels` : graphql.labels(`film_personnages_acteurs_personnages`), .`nom`, `film` : head([ (`film_personnages_acteurs_personnages`)-[:`FIGURE_DANS`]->(`film_personnages_acteurs_personnages_film`:`Film`) | `film_personnages_acteurs_personnages_film` {`_labels` : graphql.labels(`film_personnages_acteurs_personnages_film`), .`titre`, .`titreFr`, .`annee`} ])} ]} ]} ] AS `personnages`
Un peu complexe au premier abord en effet. Il s’agit de code généré et comme je ne connais pas la mécanique qui l’a pondu il restera brut de fonderie. En revanche, si nous avions écrit la requête Cypher nous-même nous aurions écrit quelque chose de plus lisible :
MATCH (f:Film {titreFr:"Alice au pays des merveilles"})<-[:FIGURE_DANS]-(pa:Personnage)<-[:INTERPRETE]-(pe:Personne)-[:INTERPRETE]->(pa2:Personnage)-[:FIGURE_DANS]->(f2:Film) RETURN f,pa,pe,pa2,f2
Cette requête retourne toutes les informations pour chaque entité. J’ai essayé de ne retourner que les attributs spécifiés jusque-là mais les performances n’ont pas changé. Nous tournons en moyenne à 1,3 secondes, toujours sur un échantillon de 10 appels.
Amélioration
Comme expliqué plus haut, ces tests ont été réalisé sans optimisation de la base. Cependant un petit « profiling » de la requête pointe du doigt un point noir :

Le nombre de hits (« db hits ») ainsi que le nombre d’enregistrements transmis à l’étape suivante (« rows ») sont les indicateurs importants. Le moteur a parcouru toute la base de données afin de trouver les films vérifiant le titre donné. Créons l’index adéquat :
CREATE INDEX ON :Film(titreFr);
La nouvelle analyse est encourageante :
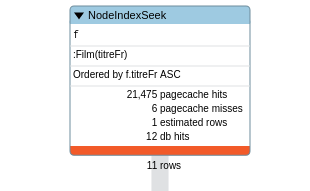
On retrouve là une problématique rencontrée régulièrement en base de données relationnelles. Aucune surprise, les statistiques confirment la justesse de la solution, les temps de réponse descendent à 89 ms pour la requête GraphQL et 51 ms pour la requête Cypher.
GraphQL et base de données graphe : le bon match ?
Ici encore une requête spécifique est plus rapide qu’une requête générée. Il ne faut pas oublier que notre exemple est un peu exagéré. GraphQL associé à une base graphe semble être un couple bien assorti. Nous devrions donc lui donner sa chance ! Une solution full stack existe, il s’agit de GRANDstack : la prochaine étape ?
Remerciements : à mes collègues relecteurs qui ont suscité quelques éclaircissements et à Nicolas Rouyer de chez Neo4j pour son aide et ses précisions.



