
GraphQL, promesse magique ou nuage de fumée ? (1/2)
Courant 2019, nous avons assisté à un buzz important autour de la technologie GaphQL dans le milieu du développement. On parlait beaucoup de GraphQL comme d’une solution révolutionnaire. Il y eu une présentation de son utilisation par un expert en développement « front ».
Comme tout buzz c'était forcément trop beau pour être vrai. L'engouement était exagéré. Il fallait apaiser l'atmosphère et remettre les choses à leur place. Il manquait aussi le côté « implémentation » la partie « back ». J'ai donc voulu étudier la technologie pour vérifier cette présomption avec plusieurs objectifs en ligne de mire :
- Présenter la vision « back » ;
- Avoir la capacité de détecter les cas d'usages propices ;
- Rassurer quant au choix de cette technologie ;
- Aider à sécuriser les projets.
GraphQL, l’alternative à l'API REST
L’API REST est considérée comme trop verbeuse dans certains cas. GraphQL est un langage de requêtes créé par Facebook en 2012 pour minimiser la quantité d'appels à ces API. C'est une technologie dont le but est d'améliorer les performances de la communication entre le front et le back. Cela permet d'alléger les infrastructures nécessaires, et également d'en diminuer le coût. Comme présenté par la Fondation GraphQL, la puissance du graphe réside dans sa ressemblance à notre façon de penser, de concevoir notre environnement. Comment aller jusqu'au bout de la logique orientée graphe ? Pourquoi ne pas combiner GraphQL avec une base de données graphe ?
Tutoriel : crée un POC pour mettre GraphQL à l’épreuve
Le matériel : que faut-il pour monter un POC avec GraphQL
Pour les facilités qu’elle apporte, j’ai utilisé une machine virtuelle VirtualBox. Elle est constituée de 6 cœurs à 2,6GHz et 16Go de mémoire. L’OS installé est Linux Mint 19.3, et les SGBD choisis sont PosgreSQL 11.7 (première partie du POC avec une base relationnelle) et Neo4j 3.5.14 (seconde partie avec une base graphe). Ces choix sont subjectifs. PostgreSQL parce que j’ai une attirance et un plaisir à travailler avec, et quant à Neo4j, il s’agit du leader du marché en matière de base de données graphes, il est à l’origine du langage de requêtage Cypher dérivé en OpenCypher et utilisé par d’autres acteurs. Un premier projet avec ce produit m’a envouté ! Alors, continuons… L’IDE est Spring Tool Suite 4. Les requêtes aux API REST et GraphQL sont effectuées avec Postman.
GraphQL et bases de données
Pour cette étude le cas étudié est la base de films d'Imdb car volumineuse et donc propice aux tests de performance. Elle contient 2 millions de films/séries TV, 2 millions de personnages et 9 millions de personnes associées et est récupérable à l’adresse https://www.imdb.com/interfaces/. Pour intégrer ces données voici le modèle que j’ai conçu :
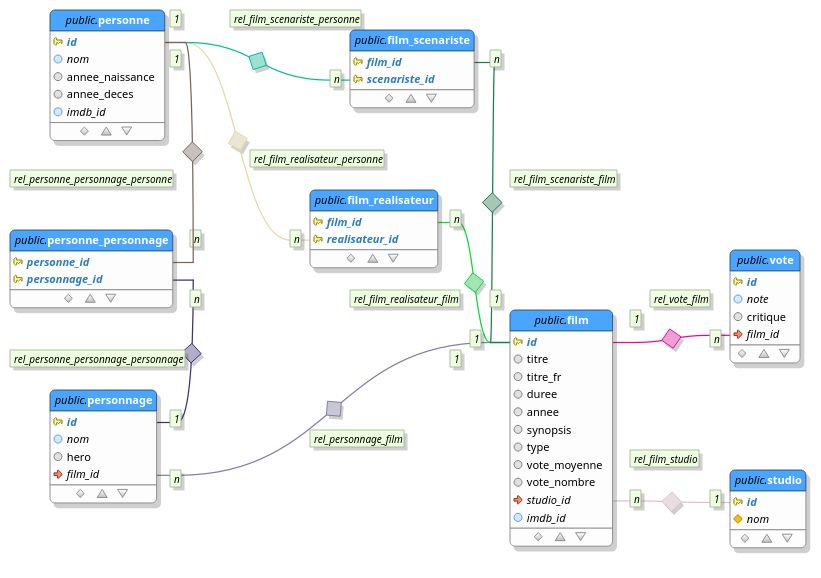
Des index sont ajoutés pour les propriétés impliquées dans la recherche (les titres de films). Je me suis focalisé sur les relations entre les films et les acteurs :
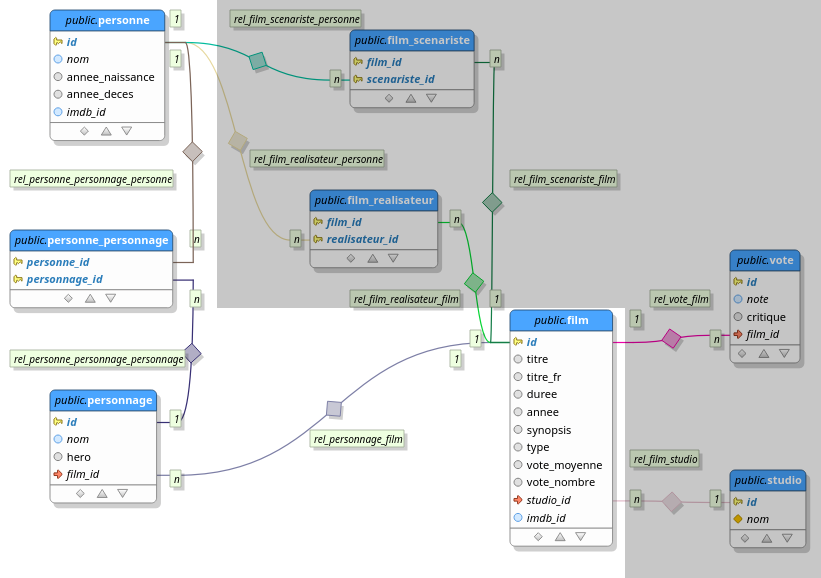
Principes des API GraphQL et REST
Prenons l’exemple d’action : lister les acteurs d’un film donné (dont nous connaissons l’identifiant).
Actions à mener avec une solution REST
- Récupération du film via un GET à l’URL /api/films/{id du film}
- Récupération des personnages via un GET à l’URL /api/films/{id du film}/personnages
- Récupération des acteurs via autant d’appels GET que de personnages à l’URL /api/personnages/{id du personnage}/acteurs
Actions à mener avec une solution GraphQL :
Récupération de toute la grappe avec un seul appel contenant la requête :
{ Film(id:{id du film}) { titre titreFr annee personnages { nom acteurs { nom } } } }
Effectivement, d’un point de vue « réseau » GraphQL est vainqueur, et ce, sur 2 points :
- En nombre de requêtes : plus il y a de personnages plus y a d’appels client-serveur avec REST
- En volumétrie : GraphQL permet de lister les données souhaitées là où REST enverra la totalité des propriétés de chaque objet (même celles que nous ne voulons pas afficher)
Création du POC GraphQL : architecture du back
JHipster a été utilisé pour créer une base applicative complète. Voici le visuel de JDL Studio où nous construisons le modèle de données : JHipster ne possède pas de plugin pour générer le code GraphQL. Nous allons donc procéder manuellement. Commençons par embarquer les librairies nécessaires. Il faut ajouter au pom.xml 2 propriétés et quelques dépendances :
<graphql.version>5.10.0</graphql.version> <kotlin.version>1.3.10</kotlin.version>
<dependency> <groupId>com.graphql-java-kickstart</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>${graphql.version}</version> </dependency> <!-- to embed GraphiQL tool --> <dependency> <groupId>com.graphql-java-kickstart</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>${graphql.version}</version> <scope>runtime</scope> </dependency> <!-- to embed Altair tool --> <dependency> <groupId>com.graphql-java-kickstart</groupId> <artifactId>altair-spring-boot-starter</artifactId> <version>${graphql.version}</version> <scope>runtime</scope> </dependency> <dependency> <groupId>com.graphql-java-kickstart</groupId> <artifactId>playground-spring-boot-starter</artifactId> <version>${graphql.version}</version> <scope>runtime</scope> </dependency>
Un peu de configuration dans Spring Boot, ajouter à application.yml :
graphql: servlet: mapping: /graphql enabled: true
Ceci active la servlet (pour le endpoint GraphQL) et limite la recherche des fichiers de configurations au répertoire /src/main/resources/graphql. Par défaut tous les fichiers *.graphqls seront interprétés. Décrivons le modèle à travers le fichier entites.graphqls dont voici l’extrait qui nous intéressera :
type Film { id: ID! titre: String titreFr: String duree: Int annee: Int synopsis: String type: FilmType voteMoyenne: Float voteNombre: Int imdbId: String votes: [Vote] personnages: [Personnage] studio: Studio realisateurs: [Personne] scenaristes: [Personne] }
type Personnage { id: ID! nom: String! hero: Boolean film: Film! acteurs: [Personne!]! }
type Personne { id: ID! nom: String! anneeNaissance: Int anneeDeces: Int imdbId: String personnages: [Personnage] filmRealises: [Film] filmScenarises: [Film] }
La première requête GraphQL
Commençons modestement par récupérer les données d’un film. Mais avant d’y arriver il faut expliquer à notre moteur quelles seront les « root queries » qu’il devra servir. Nous créons ainsi le fichier queries.graphqls :
type Query { filmById(id: ID!): Film filmsByTitreFr(titreFr: String!): [Film] }
Ces requêtes sont le point de départ, les racines, des grappes d’objets que nous allons demander au serveur. A cette description doit correspondre l’implémentation. Il s’agit du « query resolver », il doit implémenter l’interface GraphQLQueryResolver :
@Component public class QueryResolver implements GraphQLQueryResolver { @Autowired private FilmRepository filmRepository; public Optional<Film> filmById(Long id) { return filmRepository.findById(id); } public List<Film> filmsByTitreFr(String titreFr) { return filmRepository.findByTitreFr(titreFr); } }
Je vous passe les détails de la DAO FilmRepository… Mais nous retrouvons bien les méthodes déclarées précédemment. Lançons-nous, envoyons la requête :
{ filmById(id: 1518508) { titre } }
Et voilà :
{ "data": { "filmById": { "titre": "Angel Has Fallen" } } }
GraphQL permet de choisir finement les données à récupérer :
| Requête | Réponse |
|
{ filmById(id: 1518508) { titre titreFr annee } } |
{ "data": { "filmById": { "titre": "Angel Has Fallen" "titreFr": "La chute du président" "anee": 2019 } } } |
Un premier niveau de récursion
Maintenant, si nous essayons de récupérer les personnages comme ceci...
{ filmById(id: 1518508) { titre titreFr annee personnages { nom } } }
...nous obtenons cette trace :
[...] --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' fetching field '/filmById/annee' using data fetcher 'com.coxautodev.graphql.tools.MethodFieldResolverDataFetcher'... --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' field '/filmById/annee' fetch returned 'java.lang.Integer' --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' completing field '/filmById/annee'... --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' fetching field '/filmById/personnages' using data fetcher 'com.coxautodev.graphql.tools.MethodFieldResolverDataFetcher'... --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' field '/filmById/personnages' fetch returned 'org.hibernate.collection.internal.PersistentSet' --DEBUG graphql.execution.ExecutionStrategy : '3752384b-894b-4130-9a19-807ca23970d0' completing field '/filmById/personnages'... --ERROR graphql.GraphQL : Execution '3752384b-894b-4130-9a19-807ca23970d0' threw exception when executing : query : [...] Caused by: org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.sqli.tlse.ct.graphql.domain.Film.personnages, could not initialize proxy - no Session
La récupération de l’année du film se passe bien, mais pour les personnages il y a un couac ! Le moteur GraphQL tente l’utilisation du getter associé à la propriété, c’est bien une collection Hibernate qui est renvoyée. Cependant la session Hibernate est fermée puisque nous sommes en dehors du DAO. Le parcours de la liste provoque donc une exception. Remarque : remonter la session à un niveau plus haut n’est pas la solution !
D’une part, l’architecture de GraphQL n’a pas été pensée pour, cela obligerait à aller modifier des classes du moteur. D’autre part cela aurait généré des requêtes en mode « lazy » et amené au même résultat en volume de requêtes que les appels successifs de resolvers comme nous allons le découvrir. Le principe de récursion de GraphQL se base sur la notion de resolver. Dans notre cas le resolver n’a pas été trouvé alors le moteur a tenté d’utiliser l’accesseur. Nous sommes dans un film et désirons connaître les personnages de ce film. Nous devons donc créer un resolver pour l’entité “Film” contenant une méthode dont le nom est le même que la propriété désirée et qui prend en paramètre le film :
@Component public class FilmResolver implements GraphQLResolver<Film> { @Autowired private PersonnageRepository personnageRepository; public Set<Personnage> personnages(Film film) { return personnageRepository.findByFilmId(film.getId()); } }
Si nous rejouons la requête, les journaux sont plus sympathiques :
--DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' fetching field '/filmById/personnages' using data fetcher 'com.coxautodev.graphql.tools.MethodFieldResolverDataFetcher'... -Hibernate: select personnage0_.id as id1_9_, personnage0_.film_id as film_id4_9_, personnage0_.hero as hero2_9_, personnage0_.nom as nom3_9_ from personnage personnage0_ left outer join film film1_ on personnage0_.film_id=film1_.id where film1_.id=? Hibernate: select film0_.id as id1_0_0_, film0_.annee as annee2_0_0_, film0_.duree as duree3_0_0_, film0_.imdb_id as imdb_id4_0_0_, film0_.studio_id as studio_11_0_0_, film0_.synopsis as synopsis5_0_0_, film0_.titre as titre6_0_0_, film0_.titre_fr as titre_fr7_0_0_, film0_.type as type8_0_0_, film0_.vote_moyenne as vote_moy9_0_0_, film0_.vote_nombre as vote_no10_0_0_, studio1_.id as id1_12_1_, studio1_.nom as nom2_12_1_ from film film0_ left outer join studio studio1_ on film0_.studio_id=studio1_.id where film0_.id=? -DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' field '/filmById/personnages' fetch returned 'java.util.LinkedHashSet' --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' completing field '/filmById/personnages'... --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' fetching field '/filmById/personnages[0]/nom' using data fetcher 'com.coxautodev.graphql.tools.MethodFieldResolverDataFetcher'... --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' field '/filmById/personnages[0]/nom' fetch returned 'java.lang.String' --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' completing field '/filmById/personnages[0]/nom'... --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' fetching field '/filmById/personnages[1]/nom' using data fetcher 'com.coxautodev.graphql.tools.MethodFieldResolverDataFetcher'... --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' field '/filmById/personnages[1]/nom' fetch returned 'java.lang.String' --DEBUG graphql.execution.ExecutionStrategy : '29388273-8606-41d2-adba-79298edc3722' completing field '/filmById/personnages[1]/nom'...---DEBUG graphql.GraphQL : Execution '29388273-8606-41d2-adba-79298edc3722' completed with zero errors
Deux requêtes Hibernate apparaissent. La première correspond aux personnages (celle que nous attendions) et la seconde au lien “ManyToOne” défini dans l’entité Personnage vers Film. La réponse correspond bien à notre demande :
{ "data": { "filmById": { "titre": "Angel Has Fallen", "titreFr": "La chute du président", "annee": 2019, "personnages": [ { "nom": "Allan Trumbull" }, { "nom": "Mike Banning" } ] } } }
Performances avec GraphQL
Il est temps de pousser la machinerie pour évaluer ses limites. Pour cela nous allons « creuser » la base de données sur 4 niveaux : films → personnages → acteurs → personnages → films. Le cas est peu vraisemblable mais ce n’est pas l’objectif. Voici donc la requête :
{ filmsByTitreFr(titreFr: "Alice au pays des merveilles") { id titre annee personnages { nom acteurs { nom personnages { nom film { titre titreFr annee } } } } } }
La réponse « prettyfied » dépasse les 10 000 lignes, nous passerons donc de la copier… En revanche, il est intéressant d’aller voir du côté des requêtes dans les journaux. Il y a 1459 requêtes au total réparties comme suit :
- 1 select sur les films avec clause sur ‘titre_fr’. Il s’agit de la root query ;
- 11 select sur les personnages avec clause sur l’identifiant du film. Il s’agit de la récupération du premier niveau ;
- 34 select sur les personnes avec clause sur l’identifiant du personnage. Il s’agit de la récupération du deuxième niveau ;
- 34 select sur les personnages avec clause sur l’identifiant de la personne. Il s’agit de la récupération du troisième niveau ;
- 1 379 select sur les films avec clause sur l’identifiant du film. Il s’agit de la récupération du quatrième niveau avec quelques films liés aux premiers personnages (soient 11) comme vu précédemment.
Le tout prend en moyenne 4,3 secondes sur un échantillon de 10 appels. Souvenez-vous du bénéfice qu’apporte GraphQL par rapport à REST ? Les multiples appels du dernier ont été réduit en un seul appel GraphQL. Cependant, ils ont été répercutés côté serveur au niveau des resolvers et donc des requêtes vers la base de données. Afin d’avoir une référence en matière de performance codons, un endpoint REST spécifique qui retourne les mêmes données mais dont l’implémentation back consiste en une seule requête vers de la base de données. Voici la requête JPQL que nous exécutons :
select distinct f1 from Film f1 left join fetch f1.personnages p1 left join fetch p1.acteurs a left join fetch a.personnages p2 left join fetch p2.film f2 where f1.titreFr = :titreFr
Avec une application « classique », il est difficile de faire plus simple et plus efficace. Les temps d’exécution s’en trouvent bien sûr améliorés. Pour le même échantillon de 10 appels, nous atteignons maintenant une moyenne de 1,9 seconde.
GraphQL : avantages et inconvénients
Nous avons comparé les performances de GraphQL à un développement spécifique. Une implémentation de type RESTful a été volontairement évincée puisque nous pouvons estimer intuitivement qu’elle ne pouvait pas faire mieux (le nombre d’appels REST aurait été équivalent au nombre d’appels de resolvers GraphQL et donc au même nombre de requêtes en base de données, on devine que la somme des échanges réseau à ajouter ne feront qu’augmenter le temps de réponse global). Voici une matrice comparative des 3 technologies étudiées :
| Avantages | Inconvénients | |
| GraphQL | • Souplesse pour le développement du client • Minimum d’appels réseau • Volume de données optimal | • Multiplication des requêtes base de données |
| RESTful | • Souplesse pour le développement du client | • Multiplication des requêtes base de données |
| REST spécifique | • Minimum d’appels réseau • Performance back | • Rigidité de la solution • Aucune réutilisabilité |
Pour résumer, le bilan est relativement positif. La solution GraphQL offre plus de souplesse dans l’évolutivité des requêtes sans impacter le back tout en minimisant l’utilisation du réseau. En revanche l’utilisation de la base de données n’est pas amoindrie. La situation du back n’est pas désespérée, plusieurs techniques peuvent nous aider…
Comment optimiser GraphQL
La situation du back n’est pas désespérée. Plusieurs techniques peuvent nous aider.
Ajout de cache
Une fois le cache configuré dans notre POC les performances s’en trouvent grandement améliorées. La moyenne du temps d’exécution passe à 90 ms (échantillon de 10 appels). Le test a été fait en mode extrême. L’ajout de cache couvre toutes les entités au point qu’après une première exécution l’ensemble des données s’y retrouve enregistré. La première requête prend entre 7 et 8 secondes. Les requêtes suivantes trouvent toutes leur réponse dans le cache. Dans la vraie vie, cela ne se passe pas comme ça mais on peut tout de même estimer que cette solution sera très utile.
Utilisation d’un « data loader »
Le principe d’un data loader est de capturer des requêtes sur un court laps de temps, de les réduire en une seule, de récupérer les données pour cette unique requête et de les travailler pour renvoyer les réponses adéquates aux requêtes capturées. Là aussi l’idée est de réduire les impacts sur la base de données.
Paginer
Ce principe est universel. Lorsque beaucoup de données doivent être récupérées il est de bonne pratique de les saucissonner.
Activer la compression
Il s’agit là de configurer le serveur et le client pour échanger les données au format gzip. Nous diminuons le volume de données qui transite dans le réseau. Les échanges base de données ne sont pas impactés.
GraphQL : une technologie à prendre en considération
En effet, elle amène une souplesse d’utilisation et réduit les flux réseaux (quantité et volume), tout ceci pour faciliter le développement et la maintenance d’une application « front ». La souplesse se trouve aussi côté « back ». Comme on l’a vu, pour chaque entité à récupérer, le moteur utilise un resolver. Rien n’empêche au contraire d’avoir des resolvers de types différents. Dans le cadre du POC, pourquoi ne pas aller chercher un complément d’information sur les acteurs auprès de l’API de Wikipédia ? Il peut tout aussi bien s’agir d’un annuaire LDAP, d’une API REST, de web-services SOAP, de fichiers plats...
Lors du choix de cette technologie, il faudra tout de même prêter attention à la taille des données retournées et ce sur 3 dimensions : profondeur de la grappe d’objets, taille d’un objet, nombre d’éléments. Des solutions existent pour gérer ces cas. Petit bémol, le point de la sécurité n’a pas été abordé. Il est assez vaste et nécessite une étude à part entière. Vous avez pu voir les impacts côté back d’une unique et simple requête. Il faudra surement implémenter des solutions anti-DoS. Mais ce n’est qu’un point de vigilance parmi une multitude...
Nous voilà arrivés à la fin de la première partie. Retrouvez la suite !
Article paru dans le n°242 de Programmez!



