











Comment en finir avec la fragilité des tests unitaires
Lorsque nous concevons un programme informatique, il est grandement recommandé d’écrire des tests unitaires. L’absence de tests provoque une mort lente du programme. En effet, si un programme ne comporte pas de tests, alors son code risque de pourrir. Le refactoring deviendra de plus en plus difficile et gourmand en temps. Les modifications du code introduiront toujours plus de bugs et le programme finira irrémédiablement et très rapidement par la case « il faut tout refaire » !
Cependant des tests mal conçus se concluront par le même résultat. Un simple refactoring provoque la réécriture de 50 tests, mais finalement, d’une évolution à l’autre, d’un refactoring à l’autre, d’un bug à l’autre, les tests ne valident plus rien et / ou sont abandonnés. Nous retombons alors à l’état du scenario précédent. Il reste fort à parier que vous avez déjà connu ce genre de situation, vous êtes peut-être même en plein dedans — jusqu’au cou.
En revanche, une application avec des tests bien conçus durera et sera de moins en moins sujette aux bugs. Le temps de refactoring n’augmente pas, il se stabilise. Réaliser des évolutions devient plaisant et renforce les relations avec les utilisateurs. Dans cet article, nous étudierons comment écrire ce genre de tests.
Test unitaire, kesako ?
Le test unitaire, une notion floue
D'expérience, une certaine lacune entoure la bonne réalisation des tests unitaires, peu importe l'expérience des développeurs. Il n'est jamais trop tard pour revoir les bases ! Il faut savoir que ces dernières années notre profession a énormément évolué. Comme le dit Oncle Bob dans son livre Clean Code :
« En 1997, personne n’avait entendu parler du développement piloté par les tests (…) Pour la plupart d’entre nous, les tests unitaires représentaient de petits bouts de code jetables écrits uniquement pour vérifier que nos programmes "fonctionnaient". »
D’ailleurs la définition du terme « unitaire » fait encore débat. Pour certains, un test unitaire correspond au test d’une méthode d’une classe. Pour d’autres, à un pan complet d’un programme. Pour d’autres encore, cela éprouve une fonctionnalité ou un comportement. Bref, encore une fois, difficile de trouver son chemin dans tant d’incertitudes.
La définition F.I.R.S.T.
Il existe un acronyme (expliqué également dans le livre Clean Code) qui définit le test unitaire : F.I.R.S.T.
- Fast (rapide) : nous parlons ici de dizaines, voire de centaines de tests exécutés par seconde.
- Independent (indépendant) : cela signifie qu’il ne faut pas qu’un test dépende d’un autre, chaque test doit pouvoir être exécuté seul.
- Repeatable (répétable) : vos tests doivent donner systématiquement le même résultat, quel que soit l’environnement dans lequel ils sont exécutés.
- Self-validating (autovalidation) : si le test échoue, alors il échoue ! Cela signifie qu’il ne doit pas y avoir un check manuel pour vérifier si c’est vraiment un échec ou pas.
- Thorough (complet) : l’idée est de dépasser le concept de couverture du code, avoir un code couvert à 100% n’est pas suffisant. Il faut tester les happy paths (le meilleur des mondes), les cas extrêmes qui représentent une erreur métier (exemple : un âge à 1000), les cas illégaux (exemple : un âge négatif) et aussi les cas de sécurité.
Si vous respectez ces principes, vous supprimerez énormément de complexité dans vos tests. Nous verrons ensuite comment écrire des tests qui respectent ces principes. Prenez bien en compte que vos tests ont autant, voire plus, de valeur que votre code de production, il faut y attacher autant d’attention.
La granularité des tests unitaires
Thomas Pierrain, un des pionniers du TDD (Test Driven Development) en France, distingue deux types de tests unitaires :
- Les tests unitaires « grain fin » : très rapides, avec un scope très restreint (tester une classe / ou une méthode)
- Les tests unitaires « gros grain » appelés aussi « tests d’acceptance » : rapides, avec un scope plus large (ils testent les fonctionnalités que possède le programme)
Les tests « grain fin », seront utilisés avec parcimonie et pour des cas particuliers. Par exemple, l’implémentation d’une formule mathématique complexe. On utilisera ce type de teste pour valider que la formule est appliquée correctement. Ces tests aident à la construction du système pas à l’entretenir. C’est pourquoi, il n’est pas nécessaire de conserver ce type de tests à posteriori. Souvent ce type de tests s’utilise dans des exercices de codes (katas).
Les tests « gros grain » ou tests d’acceptance seront notre fer de lance. Ils nous permettront de couvrir les comportements de notre système. Ces tests serviront de documentation vivante et garantiront la non-régression de notre programme. Nous parlons bien de tests unitaires car nous nous efforcerons de respecter les principe F.I.R.S.T.
Pour la suite nous aborderons essentiellement les tests d’acceptance.
Le piège du taux de couverture
Il est courant de voir le taux de couverture de code être utilisé comme objectif, « pour cette release, il faut passer de 70 à 90% de couverture de code » accompagné du fameux « il y aura des primes ».
Bien que l’intention soit louable cette pratique n’est pas recommandée — l’enfer est pavé de bonnes intentions. Le taux de couverture du code est un indicateur, un outil, pour identifier le code non testé de manière volontaire ou non. Avoir ce genre d’objectif, pousse les développeurs à enfreindre le « T » des principes F.I.R.S.T. Cela laisse la place à des tests fragiles qui ne sont là que pour remplir des trous dans la raquette. Qui n’ont aucune valeur métier et qui sont extrêmement chronophages.
Un des indicateurs à challenger par des objectifs quand on parle de code est le nombre de bugs en production après une release et / ou le nombre de régressions. A partir de là, nous pourrons établir une stratégie en nous appuyant sur la couverture, sur la qualité et l’efficience du code.
Des tests unitaires, ça teste quoi ?
Écrire des tests unitaires nécessite un cadre, comme nous l’avons précédemment évoqué, avoir 100% de couverture de notre application se révèle très chronophage. De plus, nous avons exclu le fait de prendre le taux de couverture comme objectif. Où se situe donc la frontière des tests unitaires ?
Pour définir des frontières, nous avons besoin d’une carte :
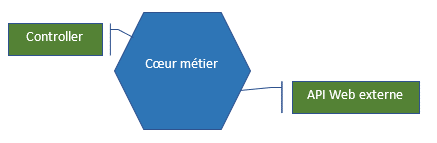
Cette carte représente une application qui sépare le code métier du code d’infrastructure (Web API externe, BDD, Controller, etc.). Cette carte est fortement inspirée d’une architecture hexagonale, que je vous recommande d’explorer plus en détail.
De manière générale, nous utiliserons les tests unitaires pour tester le cœur de notre application, donc le code métier. Nous nous efforcerons d’écrire des tests qui simuleront les comportements du code d’infrastructure.
Le terme « comportement » est lui aussi un peu abstrait et sujet à plusieurs définitions. Ici, un comportement représente une intention métier résultant d’un appel à un point d’entrée du code métier.
Nous aurons ainsi une multitude de tests unitaires qui considéreront le cœur de notre application comme une boîte noire et s’assureront que le comportement de cette boîte reste correct.
Écrire des tests unitaires
Écrire de bons tests unitaires n’est pas simple mais les principes F.I.R.S.T. vous y aideront :
Fast
Pour qu’ils soient rapides, les tests unitaires doivent exclure toute interaction extérieure (appel réseau, lecture ou écriture de fichier) qui peuvent considérablement ralentir les tests. Nous utiliserons pour cela des simulacres pour imiter le fonctionnement de ces éléments, comme des Stubs, des Mocks ou des Fakes.
Pour être facilement simulé le code de production doit être suffisamment isolé des interactions extérieures. Le pattern d’inversion de contrôle répond à cette problématique.
Par exemple, notre service de commande « OrderReceiver » doit respecter certaines règles métiers avant d’accepter une commande et la sauvegarder en base de données. L’une d’elle serait par exemple que le client doit habiter à moins de 50km du magasin. Notre test vérifiera cette règle. Nous ne voulons pas pour cela avoir besoin de monter une base de données de test et établir une connexion. Grâce au pattern d’inversion de contrôle, nous injecterons au constructeur de « OrderReceiver » une implémentation de l’interface « ISaveOrder » qui a la responsabilité de gérer les interactions avec la base de données.
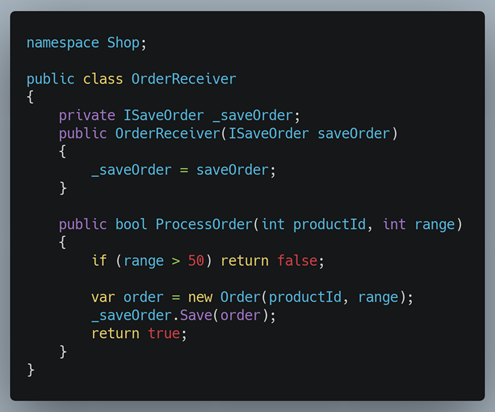
Ainsi, pour notre test, nous avons juste à créer un simulacre de « ISaveOrder ».
On peut ainsi se concentrer sur le test de notre règle métier sans être ralenti par une interaction extérieure.
Independent
Afin de vous aider à garder vos tests indépendants des autres tests, vous pouvez utiliser la règle des trois A (Arrange, Act, Assert).
Cette règle permet de bien construire un test :
- Arrange : on prépare les ressources nécessaires pour les tests, on utilisera le pattern Builder afin de masquer la complexité de l’implémentation du code.
- Act : on appelle le code à tester avec les paramètres créer précédemment dans le « arrange ».
- Assert : on vérifie que le résultat correspond à nos attentes. On peut utiliser des fonctions privées pour encapsuler des assertions complexe.
Si vous êtes plus familier avec les termes Given, When, Then, vous pourrez les utiliser à la place des AAA, ils suivent exactement le même principe. Je préfère la règle des trois A, car je la trouve plus simple à mémoriser.
Repeatable
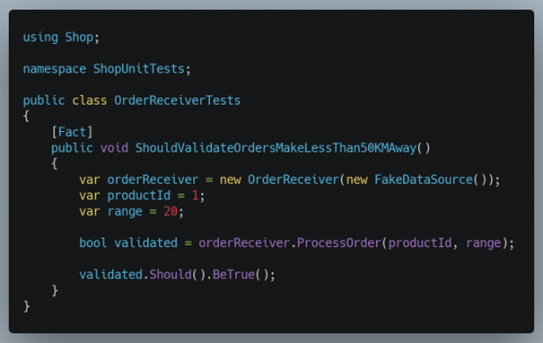
On dit aussi déterministe. Cela réfère au fait que les tests doivent pouvoir être exécutés dans différents environnements sans avoir de résultat différent. Il ne faut donc pas lier des paramètres extérieurs aux tests. Un des cas les plus courants est la gestion de date, nous avons une règle qui détermine qu’une commande doit être validée dans les 20 minutes. On envoie une date en paramètre à notre code et tout fonctionne. Mais une fois dans la CI, … BOUM ! « Que s’est-il passé ? Ça marche sur ma machine ». Vous n’avez pas pris en compte que le serveur est en date UTC, or sur votre machine les dates sont configurées en GMT+1. Voici un bon exemple de test non-déterministe :
Ajoutons la date à laquelle la commande a été enregistrée...
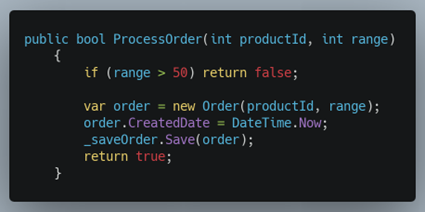
Dans cet exemple, tester que la date de création est correctement formatée ou à la bonne valeur reste difficile. Créer un service qui fournit des dates à notre système est un bon moyen de résoudre le problème. En effet, « CommandReceiver » ne sera plus responsable de la date actuelle, il appellera « DateProvider » qui lui fournira la date actuelle. Par ailleurs, récupérer la date actuelle est en fait une ressource extérieure qu’il faut isoler, nous faisons donc d’une pierre deux coups.
Ainsi nous exploiterons ce provider dans nos tests pour simuler la date actuelle et rendre nos tests déterministes.
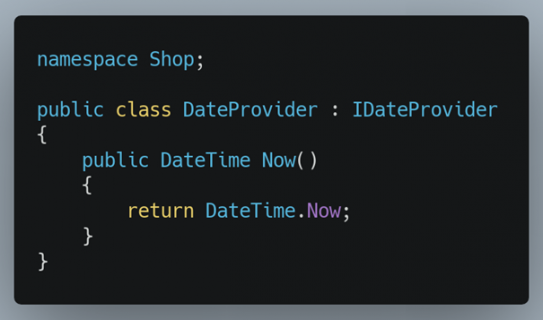
Cette abstraction semble ridicule et inutile, mais elle ne l’est pas. Si vous n’êtes pas convaincu, tentez le test chez vous. Le résultat sera soit similaire à ceci… soit d’une complexité extrême.
Self-validating
Toutes les validations doivent être codées. Il ne faut pas, par exemple, enregistrer le résultat d’un export et valider a posteriori, manuellement, que le fichier est correct. Chaque test a son assertion qui détermine la validité du test. Cela permet aux tests d’être automatisés.
Thorough
Afin de s’assurer du caractère « complet » d’un scenario de tests, il est nécessaire de tester beaucoup de cas différents. Nous nous trouvons rapidement perdus et ne pas savoir par où commencer, voire oublier des cas de tests. Afin que cela n’arrive pas je me tourne vers la technique « Z.O.M.B.I.E.S ». Cette technique, m’a été apportée par Pierre Criulanscy. Ce n’est pas un acronyme habituel, il n’est pas séquentiel comme à l’accoutumée, mais partiellement séquentiel. Il comporte deux dimensions, Z.O.M. et B.I.E. et S qui les lie :

- Z.O.M : Suivez le guide !
- Z « Zéro » : c’est le point de départ, on commence par un cas initial. On fait émerger l’interface du code (I de « Z.O.M.B.I.E.S »). On retourne des valeurs en dur.
- O « one » : on part du cas initial pour aller vers un cas d’utilisation, on remplace la valeur en dur par une valeur concrète.
- M « Many / More complex » : une fois que les comportements limites (B de « Z.O.M.B.I.E.S ») entre zéro et un (et éventuellement retour à zéro depuis un) ont été gérés dans les tests, passez à la généralisation de votre conception en traitant maintenant des scénarios plus complexes et à gestion de plusieurs éléments.
- B.I.E : révèle l’intention du code, par des comportements délimités
- B « Boundaries Behaviors » : pour ne pas oublier de tester les cas à la marge. Les happy paths ne suffisent pas.
- I « Interfaces » : faire émerger l’interface du code. Par quelle méthode on aimerait qu’il soit appelé, quels paramètres, quel type de retour.
- E « Exceptions » : il faut également tester les sad paths. Ces tests sont souvent mis de côté, mais ils représentent la pierre angulaire de la résilience du programme.
- S « Simple scenarios, Simple Solutions. » : les tests doivent décrire des scénarios et des solutions simples.
Grâce aux ZOMBIES, nous renforçons nos scénarios de tests.Ainsi, pour tester que les commandes faites à 50 Km ou moins sont acceptées on pourrait avoir ces scénarios de tests :
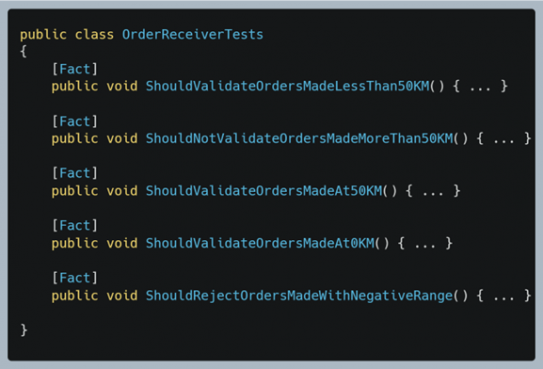
Vous constatez la distinction des cas limites (supérieur à 50 km) et des cas d’exception (distance négative).
Vous pouvez consulter le code en détail sur github :

https://github.com/anael-sqli/code-samples
Au fil de l’article, nous avons abordé de nombreux sujets ensemble. D’abord qu’un test unitaire est un concept qui se définit selon plusieurs critères : Fast, Independant, Reapetable, Self-validating et Thorough. Nous avons appris que tester l’intégralité de notre application avec des tests unitaires n’est pas nécessaire. Nous avons également remarqué qu’écrire des tests solides impose une certaine rigueur du code de production, notamment de ne pas dépendre du code extérieur au domaine. Enfin, nous n’avons plus de problème pour écrire et structurer nos tests grâces aux « Z.O.M.B.I.E.S. ».
Gardez bien à l’esprit que vos tests ont autant de valeur que le code de production et nous devons donc y accorder autant de temps et d’attention.
Il reste encore beaucoup de concepts liés aux tests que j’ai volontairement omis dans cet article, comme le TDD « Test Driven Development », qui permet d’écrire du code de production par le prisme des tests unitaires. Ou également le BDD « Behavior Driven Development » qui lui, permet de définir avec le métier les différents comportements de l’application avant de coder. Ces pratiques partent du postulat que les développeurs savent écrire des tests unitaires et il est difficile de les aborder si ce n’est pas le cas. J’espère que cet article vous a aiguillé sur la manière d’en écrire.
Bon tests et happy coding !
Références :
Oncle Bob – Robert C. Martin : http://cleancoder.com/products

Clean Code (Robert C. Martin) : https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882

Thomas Pierrain : https://2018.dddeurope.com/speakers/thomas-pierrain/

Pierre Criulanscy : https://craftacademy.substack.com/




