











Performance .Net 6 & EfCore 6, qu’en est-il ?
La sortie de .Net 5 en 2020 a mis en avant un certain nombre de gains de performance par rapport à .Net Core 3.1. La nouvelle version .Net 6 continue sur cette lancée, avec pas moins de 500 pull requests pouvant être associés à un gain de performance sur les 6500 de la release. Les ambitions sont également grandes pour EF Core 6.0 : rattraper les performances du Micro ORM qu’est Dapper.
Je vous propose donc de décortiquer quelques fonctionnalités et d’essayer de percevoir comment les changements de certaines parties du code peuvent avoir un impact fort sur les performances du runtime.
Focus sur la performance .Net 6
La recherche de performance peut s’acquérir de deux manières. D’abord, il y a la recherche de la performance pure du code. On essaye de trouver des raisonnements et une logique différente permettant d’augmenter significativement les traitements. Puis, il y a les avancés du langage et les performances qu’elle peuvent apporter. Ce que j’apprécie avec cette version de .Net 6, c’est que les développeurs ont utilisé tantôt l’une et tantôt l’autre, et parfois même les deux.
Les tests de performance avec Benchmark .Net
Avant toute chose, l’utilisation d’une librairie de benchmark est nécessaire. Benchmark .Net est une librairie destinée aux benchmarks et à la mesure de performance. Sa modularité lui octroie la possibilité de mesurer différents frameworks à la fois du .Net Core ou du Framework. Ainsi c’est le partenaire idéal pour tester les gains de performance entre .Net 5 et .Net 6, et c’est ce que ce nous utiliserons tout au long de l’article.
JIT
Le code source écrit en C# est compilé dans un langage intermédiaire (il) conforme à la spécification CLI. Le code de langage intermédiaire et les ressources, telles que les bitmaps et les chaînes, sont stockés dans une assembly, en général, avec une extension .dll.
Lorsque le programme C# est exécuté, l’assembly est chargé dans le CLR. Le CLR effectue une compilation just-in-time (JIT) pour convertir le code de langage intermédiaire en instructions machine natives. C’est donc naturellement que si l’on veut augmenter les performances du runtime .Net, la gestion de la partie Jit est un bon candidat.
En .Net 6, de nombreuses améliorations ont été ajoutées par la communauté. L’une d’elle porte sur la gestion des méthodes dites inline. L’« inlinning » est le processus d’optimisation d’un compilateur permettant de remplacer l’appel d’une fonction par son code. Bien que par définition, une méthode inline augmente la taille du programme, son principal avantage est d’offrir la possibilité d’améliorations qui ne peuvent être accessible par l’appel de la fonction (code mort, optimisation d’invariant, élimination de variables d’induction, etc. ...). Pour certaines raison, « l’inlinning » est à double tranchant côté performance : utilisé à mauvais escient, il peut réduire drastiquement les performances. Toutefois, utilisé correctement, il est peut-être extrêmement puissant.
Finalement, c’est un ensemble d’améliorations qui ont été effectuées sur la partie JIT afin de mieux comprendre le code faisant appel à la fonction inline. Pour tester les gains de performance, prenons l’exemple de la classe Utf8Formatter. Si nous regardons plus en détail le code, voici la signature de la méthode TryFormatInt64 :

Nous pouvons observer que la méthode est tagguée pour être en mode inline.
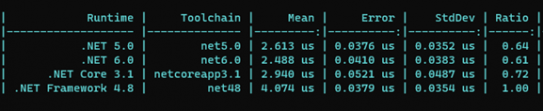
En effectuant un test avec Benchmark .NET, nous remarquons d’après le ratio que les performances ont plus que doublé par rapport à .Net Core 3 .1, et que la différence est aussi significative avec .NET 5.0
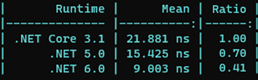
Bien d’autres améliorations sont disponibles concernant la partie JIT. La communauté a travaillé sur des améliorations concernant la dévirtualisation, le PGO Dynamique ou encore la vérification des limites.
Crossgen et AOT
Crossgen est arrivé très tôt dans le runtime de .Net Framework. Au fur et à mesure de l’avancée du framework .Net Core, le besoin s’est fait sentir de réécrire l’outil. Crossgen est un outil permettant la compilation AOT (ahead-of-time). Son but est de réduire les besoins de la compilation JIT au moment de l’exécution. La compilation AOT s’applique au moment de publication de l’application, Crossgen applique alors une pré-compilation JIT sur l’ensemble des dll et stocke le code ainsi créer dans une nouvelle section pouvant être récupérée rapidement par le runtime.
Crossgen 2 a été complétement réécrit avec une nouvelle architecture pour coller aux usages de .Net 6. En effet, ceux-ci diffèrent totalement suivant les besoins. Il peut être utilisé sur du Windows ou du Linux, dans des web app Azure ou dans des « containers », pour du web ou du desktop. La nouvelle version de Crossgen prend en compte toutes les spécifiés de projet analyser et optimiser le code in fine.
System Types
System Types étant utilisés à tout moment et dans chaque application .NET, on ne peut augmenter les performances de .Net sans passer par l’optimisation des types de la librairie « System ». Des modifications ont été apportées à certains types moins habituels comme le type version, et d’autres retouches concernent des types plus « couramment utilisés », comme Random qui a été totalement refondu. L’histoire est simple, l’algorithme utilisé jusqu’à .Net 6 était le même depuis 20 ans. Il a donc été réécrit pour améliorer les performances de la génération d’une chaîne pseudo-aléatoire sans empiéter sur la qualité dont nous avons besoin en tant que développeur. Je pense que cette refonte de l’algorithme devrait sûrement avoir un article à lui tout seul ; c’est pour cela que j’ai préféré me pencher sur un autre type que l’on utilise tous les jours et qui au cœur des applications .NET : le Guid. Ce type est présent pour fournir un identifiant unique et universel dans une application.
Etant donnée son caractère unique et universel, l’utilisation est rependue dans les applications et l’une de ses méthodes les plus utilisées reste le « parsing » (utilisé dans la désérialisation de Json par exemple). En .Net il existe plusieurs formats de Guid, avec ou sans parenthèse, accolade, séparé par un hypen. L’algorithme a été simplifié et l’utilisation de méthode inline permet de mieux gérer les cas d’extraction d’un Guid d’une chaîne de caractères.
Si on lance un test en comparant à partir de la version .Net Framework 4.8, voici ce que nous obtenons :
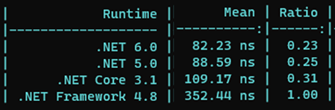
Un bond en avant a été fait entre .Net Framework 4.8 et .Net Core 3.1, puis de petite avancée jusqu’à .Net 6. Toutefois, quand on pense que le parsing de string en Guid est inévitable dans la réception de Json par une API, nous nous rendons compte qu’après 1 millions de parsing la maigre différence entre .Net 5 et 6 devient bien plus importante :
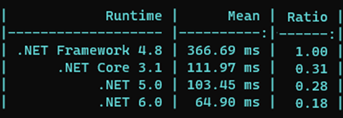
String, Collections et Linq
Les tableaux, les collections et Linq ont une place importante au cœur de .Net. La communauté a donc travaillé à réduire l’impact des traitements sur les performances du code.
Prenons le cas d’une copie d’un dictionnaire. Etant utilisé à longueur de temps, rien de plus banal que de cloner un dictionnaire pour effectuer certains traitements. Si le dictionnaire source et le dictionnaire de destination partagent le même comparateur de clé, l’astuce a consisté à copier les objets sans les hacher par la suite :
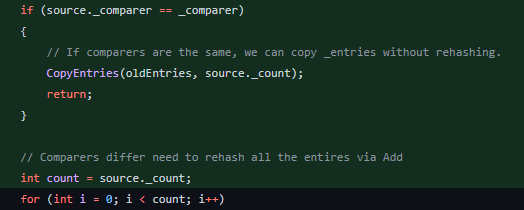
En vérifiant par un test, nous remarquons un gain de performance depuis .Net Framework 4.8 :
Sur les collections, d’autres changements ont été effectués pour améliorer un peu plus les performances.
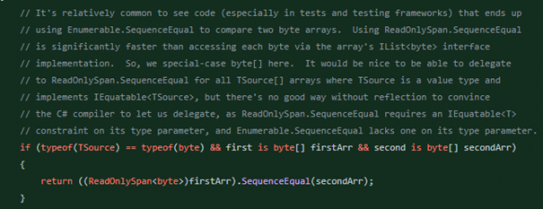
Côté Linq, une amélioration m’a interpelé concernant les tests d’équivalence entre deux Enumérables avec Enumerable.SequenceEqual. D’abord optimisé pour les byte[], une deuxième pull request est venue compléter le code pour n’importe quelle type. Au lieu de comparer les séquences directement, celle-ci se base sur la « value types » System.Span<T>. Ainsi le traitement est délégué à la méthode span ajoutant une vectorisation de la comparaison sans utiliser plus de ressource. Le seul inconvénient est que le type T doit s’y prêter correctement :
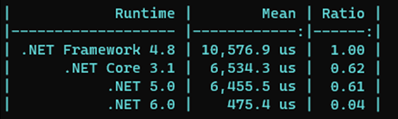
Le résultat est bluffant et nous rappelle le bienfait de la librairie System.Span sur les performances lors des traitements :
Les autres améliorations concernent la partie Distinct, Min, Max ainsi que l’ajout de nouvelles API telle que Enumerable.Zip (acceptation de 3 sources au lieu de 2).
Enfin, intéressons-nous au String. Une optimisation intéressante a été réalisée au niveau de la méthode « String.Replace(String, String) ». Certes, ce n’est pas la méthode en elle-même qui a été optimisée, mais plutôt le traitement des différents cas de Distinct. En effet, trois cas ont tiré leur épingle du jeu afin d’être optimisés dans cette version de .Net 6 :
Le cas le plus évident est lorsque nous souhaitons remplacer un caractère par un autre, souvent des caractères spéciaux comme \n. Ainsi la rapidité d’un str.Replace("\n", " ") est accrue pour la simple et bonne raison qu’elle fait directement appel à la méthode String.Replace(char, char) :

Le deuxième cas réside lors du remplacement d’un caractère unique par une valeur (unique ou non). Dans ce cas, c’est indexOf(char) qui est utilisé :
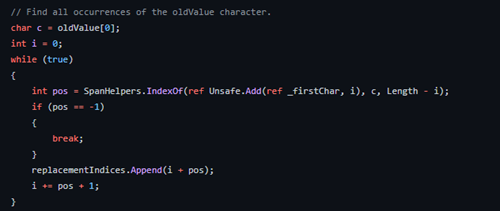
Le dernier cas survient lors du remplacement de plusieurs caractères avec l’utilisation d’un équivalent de IndexOf(string, StringComparison.Ordinal).
Si nous testons les performances de chaque cas, nous retrouvons une augmentation de performance significative dans le cas 1. L’augmentation reste tout de même honorable dans le cas 2 et 3 :
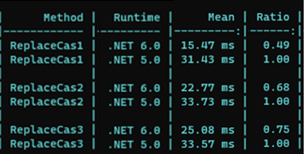
Les autres modifications de la librairie String ont porté sur l’API String.join avec la aussi l’introduction de la fonctionnalité « ReadOnlySpan<string ?> », mais également string.format avec des changements surtout issue de C#10 et la string interpolation.
IO
La librairie FileStream est l’une des plus vieilles librairies de .Net. Elle a donc a connu de nombreuses modifications année après année et était donc l’une des candidates les plus importantes à une mise à jour, sachant que l’accès au fichier est utilisé dans d’innombrable scénarios. Pour cette version .NET 6 la librairie FileStream a été complétement réécrite pour d’une part séparer les fonctionnalités en donnant plus de visibilité au code, et d’autre part faciliter les changements affectant la performance.
Deux méthodes ont été principalement revues pour offrir des gains de performance : FileStream.Seek et FileStream.Position. Le constat de départ, fait par la communauté, porte sur l’observation que les méthodes FileStream.ReadAsync et FileString.WriteAsync synchronisent l’offset du ficher de manière récurrente à chaque opération asynchrone. C’est d’ailleurs une problématique connue depuis de nombreuses années.
Les modifications apportées dans .Net 6 contourne ce problème en suivant l’offset plutôt en mémoire quand cela est possible ce qui accélère le traitement. Par la même occasion, les appels système ne sont effectués que lorsqu’ils sont explicitement requis.
Voici les résultats de ce long travail :
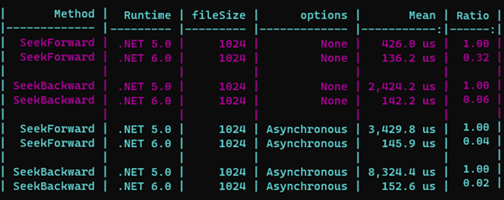
D’autres améliorations de performance ont été introduites dans cette réécriture, nous avons par exemple un travail sur la fonction de Lenght, avec pour elle aussi un accès en mémoire tant qu’il n’y a pas d’accès Write sur le fichier. Les parties Aync file IO, comme nous l’avons vu, ont bénéficié des avancées de FileStream mais également d’autres améliorations comme une meilleure gestion des allocations mémoire et de la libération. J’ai d’ailleurs réalisé les tests sur Windows, mais bien entendu, les systèmes Unix bénéficient également des mêmes gains de performance.
EF core 6.0 sur le banc des gains de performance
C’est au tour de EF Core 6.0 de passer sur le banc des gains de performance. Comme évoqué, l’ambition était grande pour cette nouvelle version, à savoir rattraper le « micro ORM » Dapper dans les scores de performance Tech Empower Fortunes. Les équipes d’EF Core ont annoncé être passées de 55% à environ 5% d’écart de performance. Si on considère les différences de feature entre Dapper et EF Core, c’est une avancée remarquable. Toutefois, il faut bien garder à l’esprit que les tests de performance concernent un scénario particulier utilisant du « no-tracking » et sans update. Il est donc possible que dans nos applications de production les performances soient être différentes. Regardons néanmoins ensemble les résultats et quelques modifications qui ont été apportées à EF Core.
Tech Empower Benchmark
Les tests Tech Empower comparent des performances de nombreux frameworks d'applications web exécutant des tâches fondamentales telles que la sérialisation JSON, l'accès aux bases de données et la composition de modèles côté serveur. Chaque framework fonctionne dans une configuration de production réaliste. Les résultats sont capturés sur des instances dans le cloud et sur du matériel physique. Les implémentations des tests sont réalisées par la communauté et toutes les sources sont disponibles sur ce dépôt GitHub.
Nous avons donc accès au code produit par chaque communauté sur les différents Framework et le C# (CSharp sur le repository) n’échappe pas à la règle.
Trois scénarios ont été retenus par l’équipe d’EF Core :
· Une implémentation qui utilise directement ADO.NET. Il s'agit de l'implémentation la plus rapide parmi les trois énumérées ici et se classe 12ième :
· Une implémentation qui utilise Dapper. Elle est plus lente que l'utilisation directe d'ADO.NET, mais reste rapide.
· Une implémentation qui utilise EF Core. C'est actuellement l'implémentation la plus lente des trois.
Pour l’heure voici les derniers résultats, malheureusement, il faudra attendre un nouveau round pour que les bénéfices des optimisations soient pris en compte.

Je vous invite donc à guetter les annonces du prochain round pour vérifier les gains.
Regroupement et recyclage des DbContext
Arrivé avec EF Core 2.0, le regroupement de contexte offre au développeur la possibilité de réutiliser un DbContext en le réinitialisant plutôt de le supprimer purement et simplement. Dans cette gestion, un pool de contexte trop grand ou illimité aurait tendance à créer des objet DbContext au fur et à mesure des besoins, sans jamais les supprimer. La conséquence serait une gestion des ressources catastrophique. Ainsi, jusqu’à la version EF Core 6.0, le pool par défaut était de 128, ce qui est déjà un nombre important. Pour les besoins du benchmark Tech Empower, la valeur a été mise par défaut à 1024. D’après les tests réalisés par l’équipe EF Core, les performances seraient augmentées de 23%.
Il faut toutefois relativiser cette amélioration, d’une part car il était déjà possible de spécifier une valeur pour la taille du pool, et d’autre part car les scénarios qui auraient besoin d’autant de Dbcontext sont limités.
Une autre amélioration touche quant à elle la manière dont EF Core interagit avec les objets ADO.NET (Par exemple DbConnection, DBCommand, DBDatareader, etc.). De base, le profilage de la mémoire a révélé un nombre élevé d’instances de ces objets. L’une des améliorations a donc consisté à réécrire les interactions pour que chaque DbContext dispose de ses propres instances dédiées qu’il réutilisera à chaque fois.
Suppression de la journalisation
Les logs peuvent être importants pour comprendre d’éventuelles problématiques sur nos applications. Dans EF Core, il est possible de voir les instructions SQL avant leur exécution ainsi que leur temps d’exécution. L’utilisateur a la possibilité de s’appuyer sur les événements grâce à classe DiagnosticSource et la gestion des instructions avec un intercepteur. Bien que cela puisse être puissant, des pertes de performance peuvent apparaître, car une fois le « diagnostic listner » ou la journalisation activé(e), le code vérifie toujours à chaque instant l’activation ou non de ces derniers.
Afin d’offrir de meilleure performance et garder toujours cette grande flexibilité, l’astuce a été de vérifier si la journalisation ou l’interception n’était pas activé et dans ce cas supprimer la journalisation pendant 1 seconde. Par conséquent, l’activation de la journalisation peut prendre jusqu’à 1 seconde, là où elle était instantanée. L’équipe a calculé que ce processus permettait d’améliorer le débit de référence de 7%.
Désactivation des contrôles de sécurité des threads
En espérant ne rien vous apprendre, EF Core n’est pas « thread safe ». Une des raisons est qu’il encapsule une connexion à une base de données qui n’autorise presque jamais l’utilisation simultanée. Etant donné que les accès concurrents sont surtout dus à un problème de développement, EF Core inclut un mécanisme de sécurité interne essayant de détecter tant bien que mal (en mode best effort) les accès concurrents et lève une exception informative.
Il s’est avéré que ce mécanisme n’est pas aussi performant que l’équipe le souhaite notamment lors des requêtes asynchrones. La problématique réside dans le fait qu’il n’y a pas réellement d’amélioration à apporter à ce mécanisme à part le désactivé totalement. Etant donné les erreurs que cela provoquera, l’équipe a donc opté pour un indicateur de désactivation offrant à ceux qui le souhaite la possibilité d’augmenter les performances (d’environ 7% d’après les tests) s’ils sont convaincus qu’aucun bug de concurrence n’existe.
Que retenir ?
Que ce soit pour .Net 6 ou EF Core 6, les performances ont été au centre des actions de la communauté, et je dois dire que j’ai été séduit par celles-ci. Même si pour EfCore 6 certaines améliorations sont difficilement transposables pour une application en production, les gains de performance sont appréciables.
Côté .Net 6, je n’ai pas fait le tour de toutes les améliorations qui ont pu être ajoutées. Etant trop nombreuses, j’ai fait le choix de n’exposer qu’une partie, et il reste de nombreuses autres améliorations, notamment sur les tableaux, le réseau, la réflexion également, la sérialisation et la désérialisation JSON, qui d’ailleurs fait l’objet d’un benchmark Tech Empower, ou encore le threading, …
Personnellement, j’ai hâte de pouvoir migrer mes applications et voir les gains que je peux tirer de .Net 6 !
Article initialement paru dans Programmez! #249